
No, not the news channel.
Lets talk about Convolutional Neural Networks CNNs also known as ConvNets. You probably should care because they power a considerable portion of your apps, whether you realize it nor not. Facebook uses it auto tag your photos, Google uses it for more than just image tagging and street sign translation but also to create weird dreams. Pinterest, Instagram, Amazon you name it, they all employ these networks in one way or another. We know CNNs are state of the art for computer vision because they have produced winners in the infamous Imagenet challenge among other challenges.
So, what exactly are CNNs?
To start with, they are neural networks(NNs). Modelled after our very own neuronal structure, neural networks are inter-connected processing elements (neurons) which process information by responding to external inputs.
You can imagine a single neuron as a black box that takes in numerical input and produces output(s) with a linear followed by a non linear activation function. When many neurons are then stacked in a column they form a layer which are interconnected to get neural networks.
For detailed explanation of NNs, see this post.
As shown above all neurons in each layer are connected to neurons in adjacent layers, making them Fully Connected (FC) layers.
CNNs go a step further, instead of generic neurons, they are modelled after our very own visual cortex. They are not only composed of multiple layers but also different kinds of layers: Input,(IN) Convolutional(CONV), Non-Linear (RELU), Pooling(POOL), Normalization (optional),Fully Connected(FC) and Output (OUT)layers.
Of interest is the Convolutional layer which performs the linear function, convolution. A convolution neuron is basically a filter that sweeps across the width and height of the input, computing the dot product between itself and input elements in its receptive field producing a 2D activation map. The dot product is computed along all three dimensions of the input: width, height and depth. For raw images the depth is 3 for RGB pixel intensities. When multiple filters stacked in a layer, then each filter produces a different 2D activation map, rendering a 3D output. The CONV layer therefore maps a 3D input to a 3D output which may differ in dimensions.
The Non-linear performs a non linear function such as tanh, sigmoid but most commonly ReLu(Rectified Linear Unit). It affects the values but leaves dimensions unchanged.
The Pooling layer performs reduces the spatial size of its input by selecting a value to represent a relatively small region in the input. Common pooling operations include the Maximum, Average and l2-norm. This layer reduces the height and width of the input but does not affect the depth.
A series of CONV-RELU-POOL layers are normally stacked together to form a bipyramid like structure where the height and weight decreases while the depth increases as the number of filters increases in higher layers.
Finally, the network is concluded with FC layers similar to traditional neural networks.
Despite their complication, CNN have competitive advantage over traditional neural networks. This comes as result of their peculiar features, some of which I have outlined below.
CNNs are not just useful to images but also time-series and speech data. They are a hot topic not only in research but in academia as well, this post has barely scratched the surface. Therefore, as the title suggests,there will be a part 2 follow up, where we walk through details of training CNN's from scratch. Thanks for reading !!!
Lets talk about Convolutional Neural Networks CNNs also known as ConvNets. You probably should care because they power a considerable portion of your apps, whether you realize it nor not. Facebook uses it auto tag your photos, Google uses it for more than just image tagging and street sign translation but also to create weird dreams. Pinterest, Instagram, Amazon you name it, they all employ these networks in one way or another. We know CNNs are state of the art for computer vision because they have produced winners in the infamous Imagenet challenge among other challenges.
 |
| facebook auto-tag |
 |
| Google 'weird' deep dream |
| Google Image translate |
So, what exactly are CNNs?
To start with, they are neural networks(NNs). Modelled after our very own neuronal structure, neural networks are inter-connected processing elements (neurons) which process information by responding to external inputs.
 |
| Biological neuron |
 |
| Artificial Neuron |
You can imagine a single neuron as a black box that takes in numerical input and produces output(s) with a linear followed by a non linear activation function. When many neurons are then stacked in a column they form a layer which are interconnected to get neural networks.
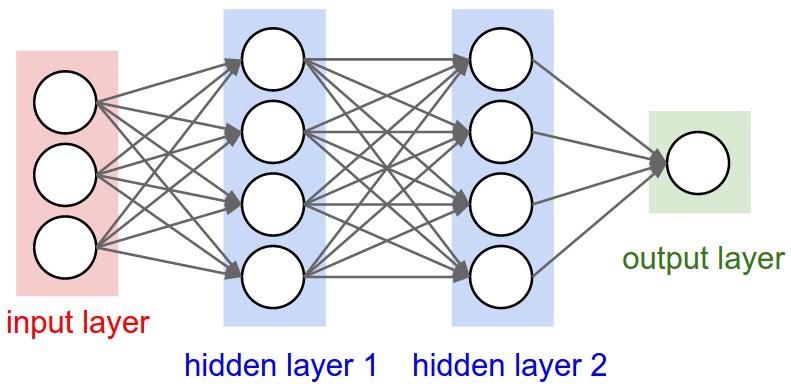 |
| Shallow Neural Network of Fully Connected layers |
 |
| Deep Neural Network |
For detailed explanation of NNs, see this post.
As shown above all neurons in each layer are connected to neurons in adjacent layers, making them Fully Connected (FC) layers.
CNNs go a step further, instead of generic neurons, they are modelled after our very own visual cortex. They are not only composed of multiple layers but also different kinds of layers: Input,(IN) Convolutional(CONV), Non-Linear (RELU), Pooling(POOL), Normalization (optional),Fully Connected(FC) and Output (OUT)layers.
Of interest is the Convolutional layer which performs the linear function, convolution. A convolution neuron is basically a filter that sweeps across the width and height of the input, computing the dot product between itself and input elements in its receptive field producing a 2D activation map. The dot product is computed along all three dimensions of the input: width, height and depth. For raw images the depth is 3 for RGB pixel intensities. When multiple filters stacked in a layer, then each filter produces a different 2D activation map, rendering a 3D output. The CONV layer therefore maps a 3D input to a 3D output which may differ in dimensions.
 |
| 3D Convolution |
The Non-linear performs a non linear function such as tanh, sigmoid but most commonly ReLu(Rectified Linear Unit). It affects the values but leaves dimensions unchanged.
The Pooling layer performs reduces the spatial size of its input by selecting a value to represent a relatively small region in the input. Common pooling operations include the Maximum, Average and l2-norm. This layer reduces the height and width of the input but does not affect the depth.
A series of CONV-RELU-POOL layers are normally stacked together to form a bipyramid like structure where the height and weight decreases while the depth increases as the number of filters increases in higher layers.
 |
| bi-pyramid structure |
Finally, the network is concluded with FC layers similar to traditional neural networks.
 |
| full-stack |
Despite their complication, CNN have competitive advantage over traditional neural networks. This comes as result of their peculiar features, some of which I have outlined below.
- Convolution filters can be thought of as FC neurons that share parameters across all filter-sized portions of the input. This is in contrast to FC neurons where each input feature would require a separate parameter. This leads to less memory requirement for parameter storage. Less parameters also reduce the chances of overfitting to training data.
- CNNs pick up patterns that result from order of input features. In FC, this order doesn't matter since all features are independent and their locations do not matter. On the other hand, CONV filters, have local receptive field therefore patterns that arise out of proximity or lack of therefore are easily detected. For instance CNNs can easily detect edge patterns or that eyes are close to the nose in faces.
- Spatial subsampling (Pooling) ensures insensitivity to size/position/slant variations. This is important images are unstructured data,meaning each pixel doesn't exactly represent a defined feature, a nose pixel in one selfie is most likely in another location in another selfie. A good model stays invariant to these distortions. In CNNs this is achieved by the pooling layer which places importance on the relative rather than absolute position of an image.
- Sparse and locally connected neurons eliminates the need for feature engineering. On training, the network will determine which features are important by allocating appropriate parameters to different locations. Zero-valued parameters imply that the feature is not important.
CNNs are not just useful to images but also time-series and speech data. They are a hot topic not only in research but in academia as well, this post has barely scratched the surface. Therefore, as the title suggests,there will be a part 2 follow up, where we walk through details of training CNN's from scratch. Thanks for reading !!!
Great Information you have shared, Check it once machine learning online training Hyderabad
ReplyDelete